15. Predicting Realized Volatility#
This notebook forecasts realized volatility using several approaches — from the HAR econometric model to gradient boosting. We then connect forecasts to a simple volatility trading strategy.
With ~4000 daily observations, complex models risk overfitting.
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 5
2 import pandas as pd
3 import matplotlib.pyplot as plt
----> 5 from data import download_data, build_dataset
7 plt.style.use('seaborn-v0_8-whitegrid')
8 plt.rcParams['figure.figsize'] = (12, 5)
File ~/work/Quantitative-Finance-Book/Quantitative-Finance-Book/volatility/data.py:13
11 import numpy as np
12 import pandas as pd
---> 13 import yfinance as yf
14 from pathlib import Path
17 # Data Download
ModuleNotFoundError: No module named 'yfinance'
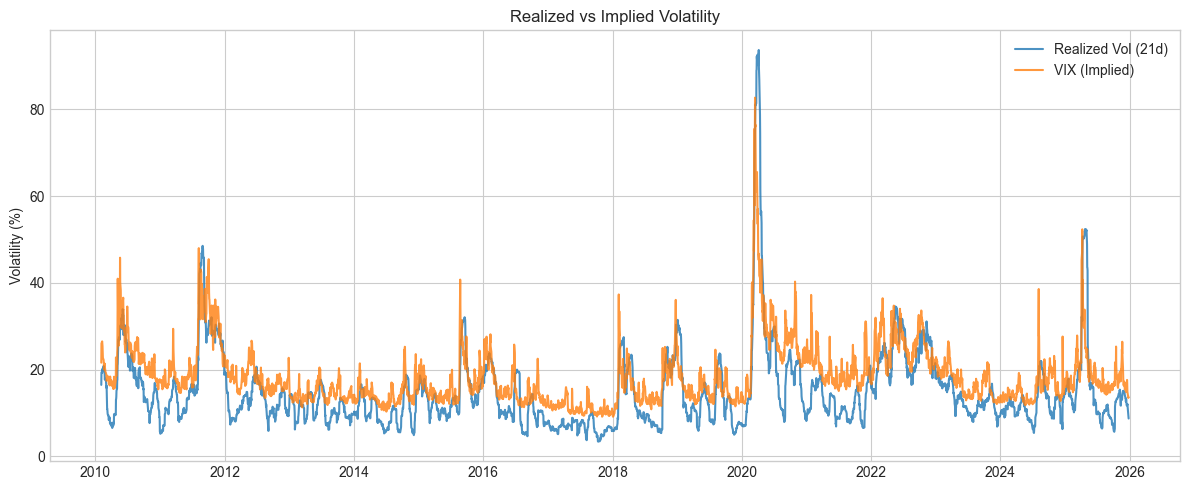
15.1. Data#
Loading cached data from /Users/patrikliba/QFB/volatility/cache.csv
Shape: (3991, 8)
Date range: 2010-02-03 to 2025-12-26
| RV_21 | RV_21_parkinson | RV_21_gk | VIX | VIX3M | VVIX | VIX_term | VRP | |
|---|---|---|---|---|---|---|---|---|
| Date | ||||||||
| 2010-02-03 | 16.479001 | 13.782122 | 13.403602 | 21.600000 | 23.000000 | 80.550003 | 1.400000 | 5.121000 |
| 2010-02-04 | 19.359712 | 14.595604 | 13.651783 | 26.080000 | 25.980000 | 91.419998 | -0.100000 | 6.720288 |
| 2010-02-05 | 19.399211 | 15.246792 | 14.608213 | 26.110001 | 26.000000 | 88.220001 | -0.110001 | 6.710789 |
| 2010-02-08 | 19.264482 | 15.389810 | 14.772060 | 26.510000 | 26.430000 | 90.010002 | -0.080000 | 7.245518 |
| 2010-02-09 | 19.928719 | 15.719228 | 15.298051 | 26.000000 | 26.040001 | 88.800003 | 0.040001 | 6.071281 |
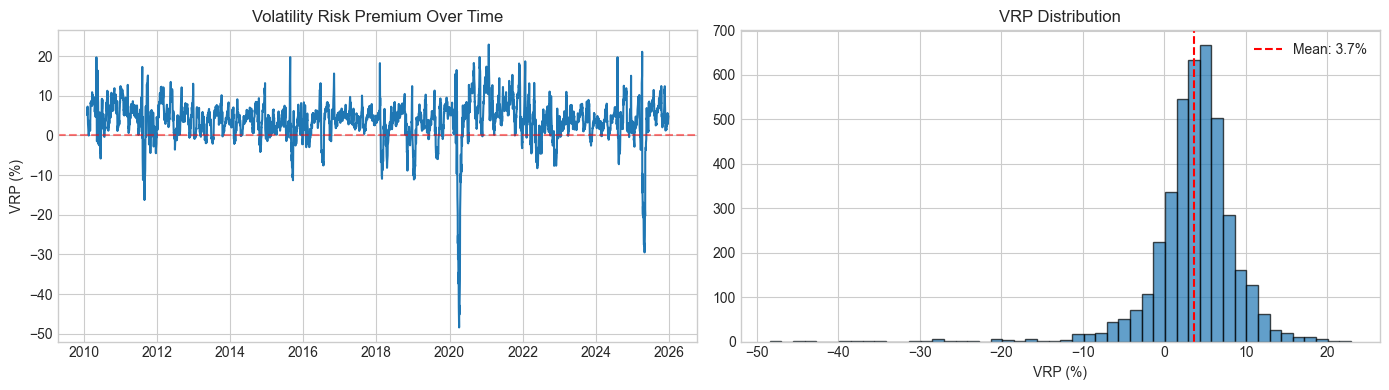
VRP Statistics:
Mean: 3.66%
Median: 4.08%
Std: 5.33%
% Positive (VIX > RV): 85.2%
15.2. Feature Engineering#
The HAR model [] uses realized volatility at multiple horizons:
where \(RV_t^{(w)}\) and \(RV_t^{(m)}\) are weekly and monthly averages. The idea is that different traders operate at different frequencies.
Features shape: (3970, 10)
Target shape: (3970,)
Date range: 2010-03-05 to 2025-12-26
| RV_lag1 | RV_week | RV_month | VIX_lag1 | VIX3M_lag1 | VVIX_lag1 | VIX_term_lag1 | VRP_lag1 | RV_parkinson_lag1 | RV_gk_lag1 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Date | ||||||||||
| 2010-03-05 | 15.789149 | 16.855651 | 18.716341 | 18.719999 | 21.030001 | 70.510002 | 2.310001 | 2.930851 | 13.107009 | 13.243167 |
| 2010-03-08 | 16.268260 | 16.555401 | 18.706305 | 17.420000 | 20.230000 | 71.059998 | 2.809999 | 1.151740 | 13.174742 | 13.232061 |
| 2010-03-09 | 10.950559 | 15.238995 | 18.305869 | 17.790001 | 20.260000 | 70.900002 | 2.469999 | 6.839442 | 12.199828 | 12.906341 |
| 2010-03-10 | 10.957554 | 14.040912 | 17.903886 | 17.920000 | 20.160000 | 71.489998 | 2.240000 | 6.962446 | 11.510836 | 11.956954 |
| 2010-03-11 | 10.257790 | 12.844662 | 17.474996 | 18.570000 | 20.510000 | 76.199997 | 1.940001 | 8.312210 | 11.232902 | 11.680056 |
Feature correlations with target (RV_21):
RV_lag1 : 0.992
RV_week : 0.973
RV_parkinson_lag1 : 0.959
RV_gk_lag1 : 0.954
VIX_lag1 : 0.833
RV_month : 0.826
VIX3M_lag1 : 0.796
VVIX_lag1 : 0.478
VIX_term_lag1 : -0.498
VRP_lag1 : -0.639
HAR features: ['RV_lag1', 'RV_week', 'RV_month']
All features (10): ['RV_lag1', 'RV_week', 'RV_month', 'VIX_lag1', 'VIX3M_lag1', 'VVIX_lag1', 'VIX_term_lag1', 'VRP_lag1', 'RV_parkinson_lag1', 'RV_gk_lag1']
15.3. Train-test split#
Train: 3221 samples (2010-03-05 to 2022-12-30)
Test: 749 samples (2023-01-03 to 2025-12-26)
Split: 81% / 19%
15.4. Models#
HAR coefficients:
RV_lag1: 1.1599
RV_week: -0.1336
RV_month: -0.0441
intercept: 0.2659
Ridge trained with all features
Gradient Boosting trained with all features
| RMSE | MAE | R2 | |
|---|---|---|---|
| Model | |||
| GradientBoosting | 1.110 | 0.580 | 0.976 |
| Ridge | 1.112 | 0.559 | 0.976 |
| HAR | 1.185 | 0.549 | 0.973 |
| Naive | 1.221 | 0.509 | 0.971 |
| VIX | 6.256 | 4.862 | 0.239 |
15.5. Results#
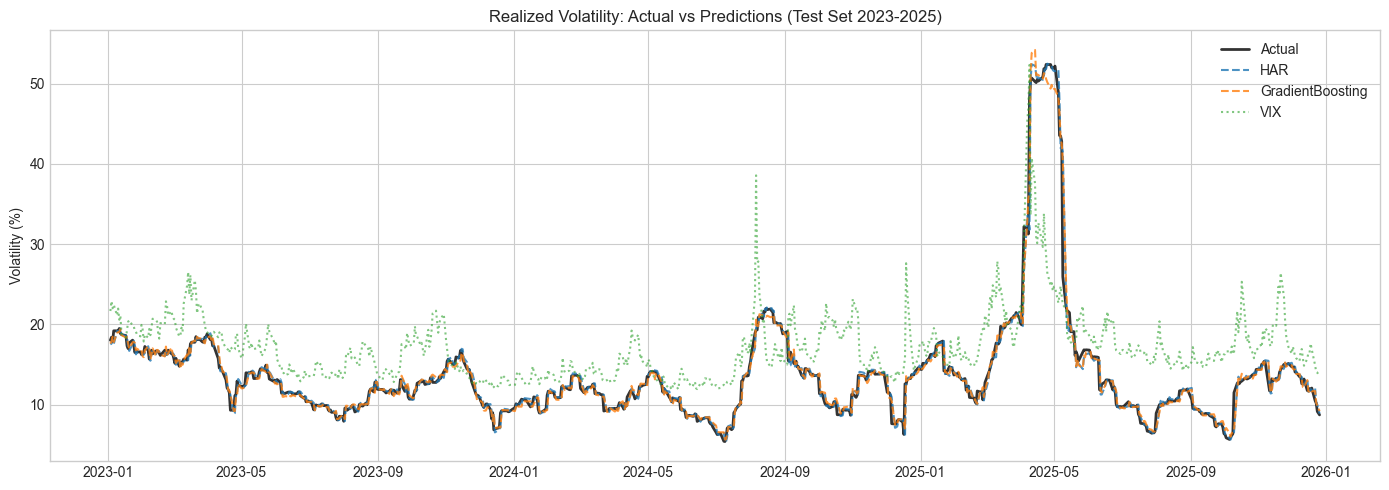
All RV-based models perform similarly (R² ~0.97). GradientBoosting wins by a small margin—only ~6% better RMSE than HAR. VIX is a poor predictor because it systematically overshoots (the volatility risk premium). Volatility is highly persistent, so even “yesterday’s RV” achieves high R².
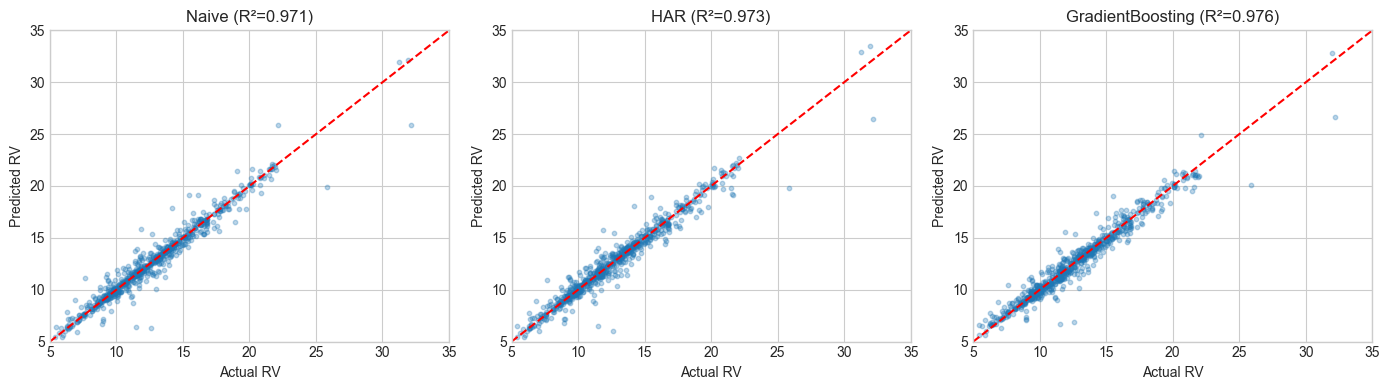
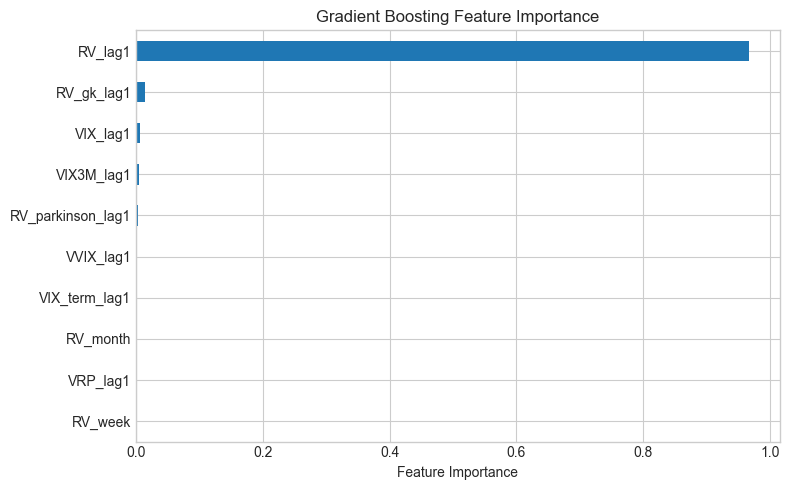
HAR basically matches the ML models despite having only 3 features. RV_lag1 does most of the work — volatility clustering means yesterday’s value is already a strong predictor. VIX consistently overshoots because of the risk premium, which makes it a poor direct predictor of realised vol.
15.6. From Prediction to Trading#
The hedging notebooks (trading/01_bs_hedging_pnl.ipynb) showed that gamma/theta PnL depends on:
Note the variance (squared), not volatility. This means:
If \(\hat{RV} < \text{VIX}\): options are expensive, so sell gamma and collect theta
If \(\hat{RV} > \text{VIX}\): options are cheap, so buy gamma and pay theta
A vol spike from 30% to 40% hurts more than one from 15% to 20% because PnL scales with variance.
Strategy Performance (Test Set 2023-2025, 3.0 years)
Notional: $10,000
=====================================================================================
Strategy Total PnL Annual % Sharpe MaxDD $ MaxDD %
-------------------------------------------------------------------------------------
Always Short (sell VRP) $ 620 2.1% 3.58 $ 393 3.93%
Naive (RV_lag1) $ 1,486 5.0% 9.83 $ 4 0.04%
HAR $ 1,488 5.0% 9.86 $ 4 0.04%
GradientBoosting $ 1,489 5.0% 9.87 $ 4 0.04%
The near-zero drawdown for Naive/HAR/GradientBoosting looks too good. What’s happening:
RV is highly persistent (R² = 0.99), so the forecast almost always gets the sign right vs VIX
When RV spikes above VIX, the forecast also spikes, so we flip to long gamma at the right time
2023-2025 was relatively calm—no blowups like March 2020
Transaction costs from frequent flipping and execution slippage during vol spikes would reduce returns. The “Always Short” strategy shows what happens without forecasting: 4% drawdown when RV exceeds VIX.
15.6.1. Connection to the hedging framework#
The PnL here matches what we derived in the hedging notebooks: a delta-hedged option has PnL \(\propto (\sigma_r^2 - \sigma_i^2)\). Short gamma profits when realized variance is below implied; long gamma profits when it’s above.
For \(10,000 notional, we get ~\)500-1500 annual PnL (5-15% returns), which matches typical VRP harvesting performance. Real-world returns are lower due to transaction costs and execution slippage.
Forecasting helps because “always short” gets crushed during vol spikes—losses are convex in variance.
Regime Analysis: HAR Strategy
============================================================
Days SHORT gamma: 668 (89.2%)
Avg variance diff: -136.5 bps²
PnL contribution: $1,054
Days LONG gamma: 81 (10.8%)
Avg variance diff: 463.3 bps²
PnL contribution: $434
'Always Short' loss on days HAR went long: $434
This is the loss avoided by using HAR forecasts!
| Annual Return (%) | Sharpe | Max Drawdown (%) | Calmar | Win Rate (%) | Profit Factor | |
|---|---|---|---|---|---|---|
| Strategy | ||||||
| Always Short (sell VRP) | 2.1 | 3.58 | 3.93403 | 0.5 | 89.7 | 2.41 |
| Naive (RV_lag1) | 5.0 | 9.83 | 0.03937 | 127.0 | 98.3 | 206.74 |
| HAR | 5.0 | 9.86 | 0.03937 | 127.2 | 98.4 | 250.09 |
| GradientBoosting | 5.0 | 9.87 | 0.03937 | 127.3 | 98.7 | 278.23 |
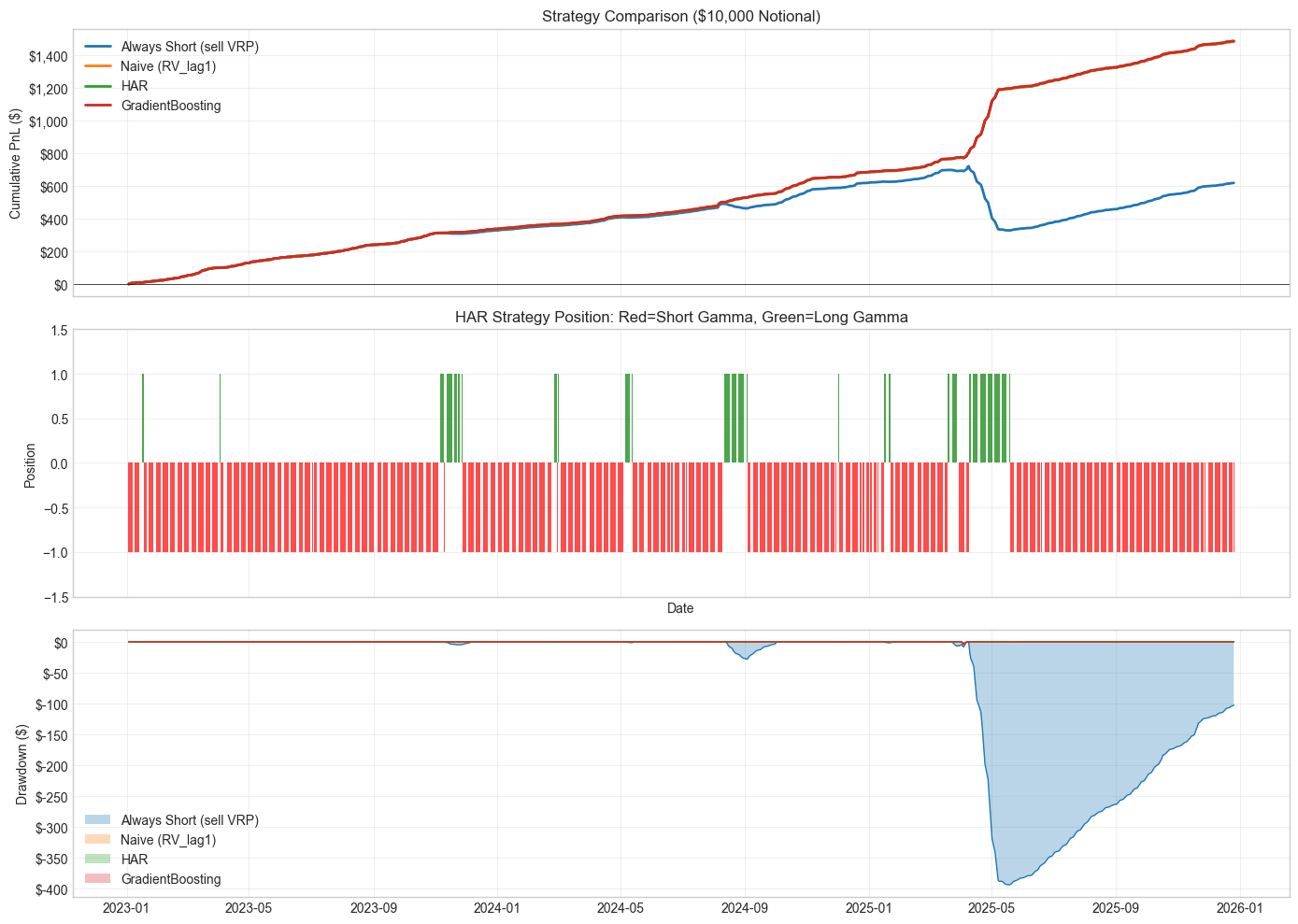
TODO: walk-forward cross-validation to check if these results hold before 2023. The test period (2023-2025) was relatively calm — would be good to see how this holds through a vol spike like March 2020.