8. Pricing American Options by Finite Difference#
Replicating the Finite Difference implementation in [Longstaff and Schwartz, 2001].
Replicating the values in Table 1.
Completely replicating the Table 1, as in the paper (last cell of the code)
8.1. Background#
The Black-Scholes PDE for a derivative \(V(S,t)\) is:
Log-transformation: Setting \(X = \log(S)\) simplifies to constant coefficients:
Discretization schemes:
European (FTCS): Forward in time, central in space - explicit scheme
American (BTCS): Backward in time, central in space - implicit scheme with early exercise constraint
For American options, at each time step we enforce: \(V \geq \max(K - S, 0)\)
8.2. LSMC Helper Functions#
We define the LSMC pricer from Longstaff and Schwartz [2001] here for benchmarking the finite difference results.
8.3. European Put: Explicit Scheme (FTCS)#
For European options, we use an explicit scheme (Forward Time, Central Space):
Known initial condition: \(V(S, T) = \max(K - S, 0)\)
March forward in time from \(t=0\) to \(t=T\)
Boundary conditions: \(V \to Ke^{-r(T-t)}\) as \(S \to 0\), and \(V \to 0\) as \(S \to \infty\)
8.4. American Put: Implicit Scheme (BTCS)#
For American options, we use an implicit scheme (Backward Time, Central Space):
Known terminal condition: \(V(S, T) = \max(K - S, 0)\)
March backward in time from \(t=T\) to \(t=0\)
At each step, solve linear system then enforce early exercise: \(V \geq \max(K - S, 0)\)
Uses LU factorization for efficient repeated solves
8.4.1. Define table replicating functions#
Finite Difference European Put Pricing
S vol T | FD European | BS European | Difference | Runtime
----------------------------------------------------------------------
36 0.20 1 3.8445 3.8443 0.000170 0.3953
36 0.20 2 3.7631 3.7630 0.000087 0.3942
36 0.40 1 6.7114 6.7114 0.000045 0.3940
36 0.40 2 7.7001 7.7000 0.000044 0.3933
38 0.20 1 2.8515 2.8519 -0.000441 0.4087
38 0.20 2 2.9903 2.9906 -0.000300 0.3969
38 0.40 1 5.8341 5.8343 -0.000217 0.3951
38 0.40 2 6.9787 6.9788 -0.000128 0.3958
40 0.20 1 2.0655 2.0664 -0.000911 0.3955
40 0.20 2 2.3553 2.3559 -0.000594 0.3967
40 0.40 1 5.0592 5.0596 -0.000439 0.3951
40 0.40 2 6.3257 6.3260 -0.000273 0.3938
42 0.20 1 1.4640 1.4645 -0.000500 0.3959
42 0.20 2 1.8410 1.8414 -0.000334 0.3952
42 0.40 1 4.3785 4.3787 -0.000241 0.4002
42 0.40 2 5.7355 5.7356 -0.000142 0.3950
44 0.20 1 1.0169 1.0169 -0.000006 0.3941
44 0.20 2 1.4292 1.4292 -0.000020 0.3956
44 0.40 1 3.7828 3.7828 0.000027 0.3943
44 0.40 2 5.2020 5.2020 0.000036 0.3939
Table 1: American put values, closed form European and early exercise value
American BS European Early Ex. Runtime
Price vol T Put Put value
---------------------------------------------------------------------------
36 0.20 1 4.4860 3.8443 0.6417 1.0091
36 0.20 2 4.8477 3.7630 1.0847 1.0152
36 0.40 1 7.1087 6.7114 0.3973 1.0168
36 0.40 2 8.5140 7.7000 0.8139 1.0156
38 0.20 1 3.2563 2.8519 0.4044 1.0215
38 0.20 2 3.7507 2.9906 0.7602 1.0200
38 0.40 1 6.1542 5.8343 0.3198 1.0123
38 0.40 2 7.6746 6.9788 0.6958 1.0167
40 0.20 1 2.3185 2.0664 0.2521 1.0197
40 0.20 2 2.8892 2.3559 0.5333 1.0129
40 0.40 1 5.3177 5.0596 0.2581 1.0147
40 0.40 2 6.9230 6.3260 0.5970 1.0145
42 0.20 1 1.6204 1.4645 0.1559 1.0198
42 0.20 2 2.2161 1.8414 0.3748 1.0207
42 0.40 1 4.5877 4.3787 0.2090 1.0121
42 0.40 2 6.2499 5.7356 0.5143 1.0132
44 0.20 1 1.1126 1.0169 0.0957 1.0126
44 0.20 2 1.6930 1.4292 0.2638 1.0115
44 0.40 1 3.9526 3.7828 0.1698 1.0162
44 0.40 2 5.6465 5.2020 0.4445 1.0143
Switching to sparse matrices with SuperLU drops runtime from ~20s to ~0.5s per option. The tridiagonal structure means LU factorization is O(Nx) instead of O(Nx³).
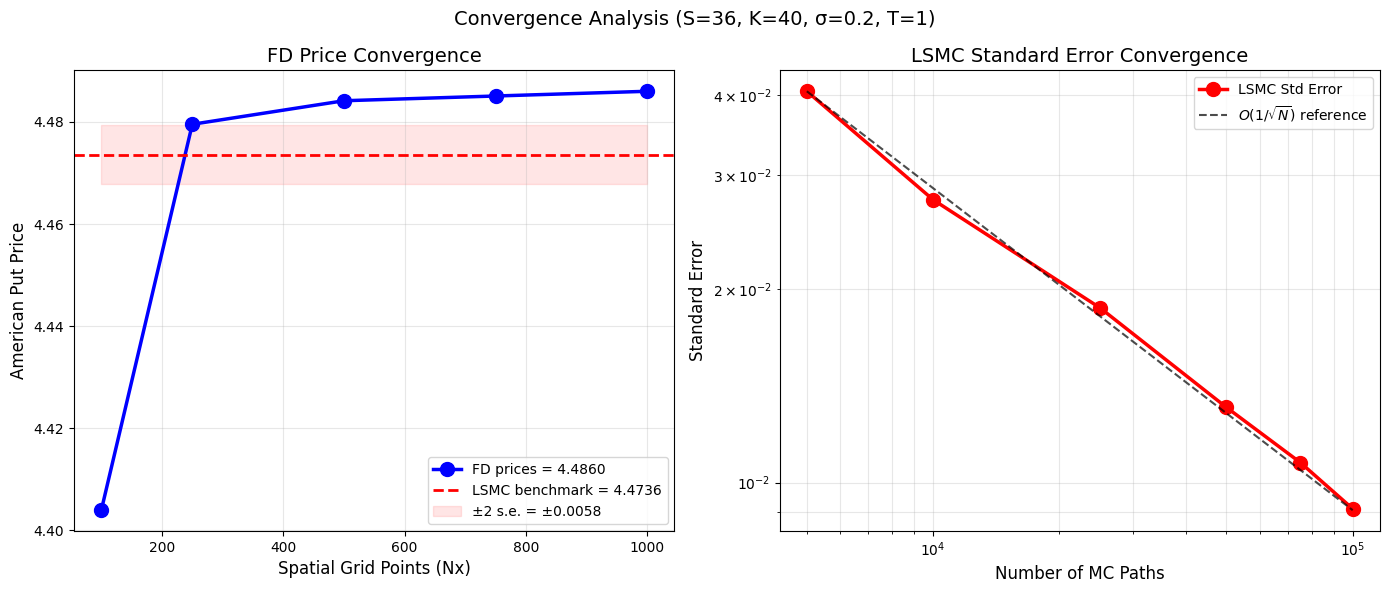
8.4.1.1. Convergence analysis#
Computing LSMC benchmark value with 1 million paths...
LSMC benchmark: 4.473597 (s.e. = 0.002910)
Testing FD convergence...
Testing LSMC standard error convergence...
==================================================
CONVERGENCE SUMMARY
==================================================
FD (Nx=1000, Nt=40000): 4.486006
LSMC benchmark: 4.473597 ± 0.002910
Difference: 0.012409
FD within 2 s.e. of LSMC: False
Question: So, why does it seem that FD is diverging from the MC price?
Noting that {cite:t}LongstaffSchwartz2001 proposes the LSMC method, so we are comparing the LSMC against FD.
To eliminate any doubts (TODO) implement binomial tree as the reference and compare both LSMC and FD against binomial tree price.